第三篇:锁的由来,并发三特性全解析
- 面试宝典
- 时间:2021-11-09 23:07
- 6866人已阅读
🔔🔔🔔好消息!好消息!🔔🔔🔔
有需要的朋友👉:联系凯哥
![]() 文章目录
文章目录
![]() 一、前言
一、前言
不管什么语言,并发的编程都是在高级的部分,因为并发的涉及的知识太广,不单单是操作系统的知识,还有计算机的组成的知识等等。说到底,这些年硬件的不断的发展,但是一直有一个核心的矛盾在:CPU、内存、I/O设备的三者的速度的差异。这就是所有的并发的源头。
CPU与内存:缓存,CPU增加了缓存,以均衡与内存的差异;(但是带来可见性问题)
CPU与IO设备:进程、线程,操作系统增加了进程、线程,以分时复用CPU,进而均衡CPU与I/O设备的速度差异;(但是带来原子性问题)
编译程序指令重排序,编译程序优化指令执行次序,使得缓存能够得到更加合理的利用。(但是带来有序性问题)
常见地,synchronized和Lock都可以同时解决原子性、可见性、有序性三个问题,volatile只能解决可见性和有序性两问题,要求操作必须是原子的,否则无法保证线程安全。
![]() 二、三大源头
二、三大源头
![]() 2.1 缓存导致可见性问题
2.1 缓存导致可见性问题
![]() 2.1.1 理论:从单核CPU到多核CPU
2.1.1 理论:从单核CPU到多核CPU
单核:所有的线程都是在一颗CPU上执行,CPU缓存与内存的数据一致性容易解决。因为所有线程都是同一个CPU的缓存,一个线程对缓存的写,对另外一个线程来说一定是可见的;
多核:每颗CPU都有自己的缓存,这时CPU缓存与内存的数据一致性就没有那么容易解决了,当多个线程在不同的CPU上执行时,这些线程操作的是不同的CPU缓存(CPU的解决的方案:MESI协议)。
单核CPU与多核CPU对比如下图:
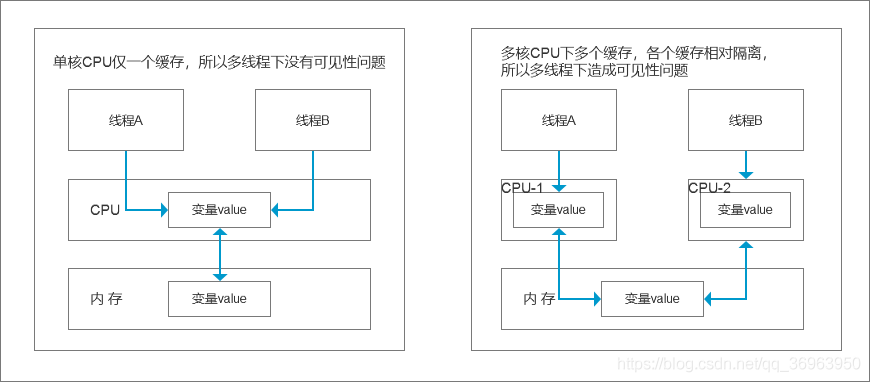
金手指:一句话小结缓存在多线程下的可见性问题
1、单核cpu,只有一个cpu,所以只有一个缓存,所有的内存都是使用这个缓存,一旦缓存内存修改,所有cpu都可见,没有可见性问题
2、多核cpu,有多个cpu,每一个cpu中一个缓存,所以n个cpu就有n个缓存,n个缓存与同一个主存交互数据,主存中的数据对于所有缓存可见,但是不同缓存之间的数据是不可见的。
多核cpu单线程下,缓存从主存中拿数据,运算,然后再存入主存,没有问题;
多核cpu多线程下,两个线程使用两个不同的cpu,两个cpu缓存都从主存中拿数据,运算,然后再存入主存,这个过程中,每一个线程都是基于自己CPU缓存里的count值来计算,但是自己的缓存数据的修改只有自己可见,造成可见性问题。
3、小结:从 CPU-缓存-主内存 到 执行引擎-工作内存-主内存,对于JMM,就是各个线程之间的工作内存不可见,所以造成可见性问题。
![]() 2.1.2 实践:多线程可见性问题
2.1.2 实践:多线程可见性问题
测试一下可见性,书写以下的代码:
public class Test {
private static long count = 0; // 类变量count
// 添加一万
private void add10K() {
int idx = 0;
// 当小于10000的时候不断加 while (idx++ < 10000) {
count += 1; } }
public static long calc() throws InterruptedException {
final Test test = new Test();
// 创建两个线程,这两个线程执行 add() 操作
Thread th1 = new Thread(test::add10K);
Thread th2 = new Thread(test::add10K);
// 启动两个线程
th1.start();
th2.start();
th1.join(); // 暂停主线程,加入thread1,thread1执行完之后执行main
th2.join(); // 暂停主线程,加入thread2,thread2执行完之后执行main return count; // 返回类变量count }
public static void main(String[] args) throws InterruptedException {
System.out.println(calc()); // 执行,返回count }}1234567891011121314151617181920212223242526272829运行结果如下:可以见得不是20000的值。
110221
原因:原子性无法保证,线程不安全,count += 1; 不是原子操作,是三步操作,可以被打断。
其他的,可见性和有序性都无法保证(即使用volatile修饰保证可见性和有序性也没用,原子性无法保证)
解决方法:同步阻塞保证原子性(synchronized)和非同步阻塞保证原子性(cas)
synchronized == for + if(cas),注意cas有一个ABA问题,虽然这里累加不涉及
我们假设线程A和线程B同时开始执行,那么第一次都会将count=0读到各自的CPU缓存里,执行完count+=1之后,各自CPU缓存里面的值都是1,同时写入内存后,我们后发现现在内存中是1,而不是我们期望的2。之后由于各自的CPU缓存里都有了count的值,两个线程都是基于CPU缓存里的count值来计算,所以导致最终count的值都是小于20000的。这就是缓存的可见性的问题。
总结:一个线程对共享变量的修改,另外一个线程能够立即看到,我们称为可见性.
![]() 2.2 线程切换带来的原子性问题
2.2 线程切换带来的原子性问题
原子性定义:我们把一个或者多个操作在CPU执行过程中不被中断的特性称为原子性。
1、时间片的引入,CPU分片执行:为了提供CPU的利用率,操作系统允许某个进程分时使用CPU,当一个进程执行IO操作时候(即count+=1 读盘、操作、写盘三操作中的读盘/写盘),这个时候这个进程将自己标记为休眠的状态,并且让出CPU使用权,让给其他线程执行,这样CPU的使用率就会上来。另一方面,如果这个时候有一个进程要进行IO操作,这个时候会发现已经有进程在IO操作,这个时候新来的进程就会等待。当上个IO进程结束的时候,会再进行这个新来的IO进程,这样IO的使用率也上去了。
2、高级语言中的语句往往不是原子性的:所有的高级的语言一条语句往往需要CPU中的多条指令。例如count+=1,至少需要三条CPU指令:
指令1:首先,需要把变量count从内存加载到CPU的寄存器;
指令2:之后,在寄存器中执行+1操作;
指令3:最后,将结果写入内存(缓存机制导致可能写入的是CPU缓存而不是内存)
3、操作系统任务切换,可以发生在任何一条CPU指令执行完。注意,是CPU指令,而不是高级语言里的一条语言,所以,高级语言中的一条语句是可以被中途打断的。
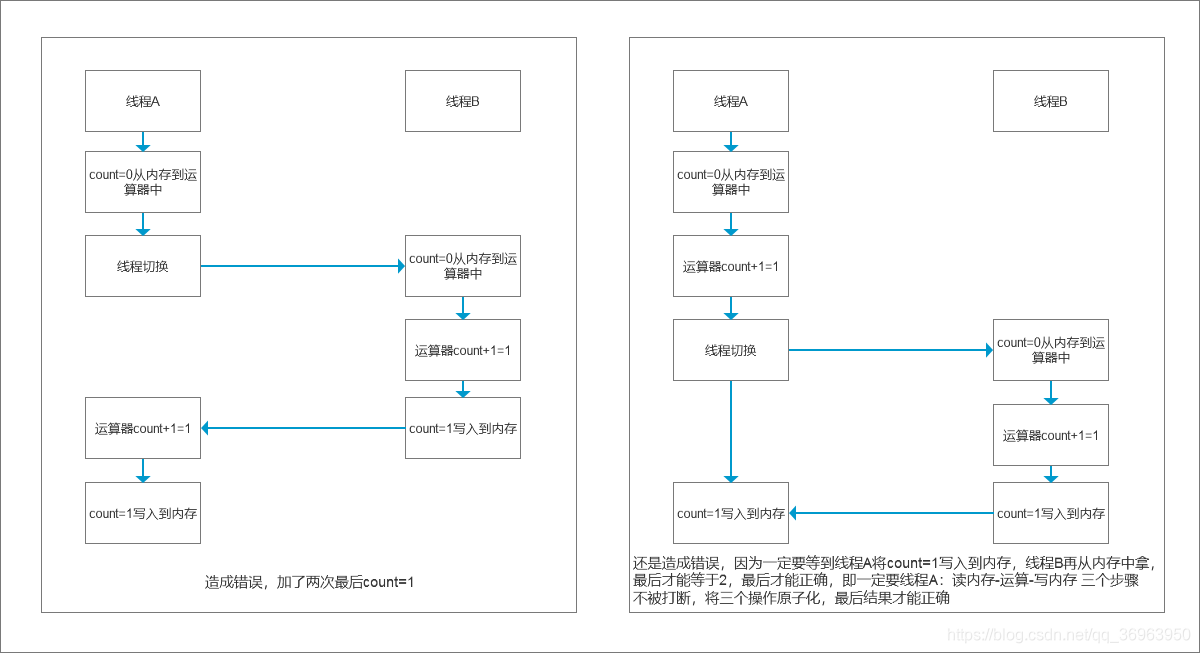
上面说的是,读磁盘-计算-写磁盘,这里演示的是 读内存-计算-写内存,实际上是一样的。
金手指:一句话解析分时时间片在多线程下的原子性问题
1、如果操作系统不支持分时使用CPU,即必须一个进程执行完成之后之后,再执行下一个进程,每一个进程的执行都不会被打断,每一个进程的执行都是原子的,不存在原子性问题。
2、如果操作系统支持分时使用CPU,一个进程执行读写磁盘或者读写内存的时候,会把CPU让出来,让给其他进程使用,如果获得CPU使用权的进程和当前进程修改同一变量,造成安全问题,该问题归根结底是因为打断了对一个变量读写的原子操作。
3、小结:从 CPU-主内存 到 执行引擎-工作内存-主内存,对于JMM,就是各个线程之间的工作内存访问主内存的操作无法原子化,所以造成原子性问题。
![]() 2.3 编译优化带来的有序性问题
2.3 编译优化带来的有序性问题
![]() 2.3.1 第一,经典案例:双重检查创建单例对象
2.3.1 第一,经典案例:双重检查创建单例对象
public class Singleton {
private Singleton(){}
private static Singleton instance;
public static Singleton getInstance() { if (instance == null) {
synchronized (Singleton.class) { if (instance == null)
instance = new Singleton(); } } return instance; }}12345678910111213注意:这里的懒汉式单例没有使用volatile关键字修饰instance变量禁止重排序,所有即使使用双层if判断,也是线程不安全的。
![]() 2.3.2 第二,我们认为的new操作:instance = new Singleton();
2.3.2 第二,我们认为的new操作:instance = new Singleton();
instance = new Singleton();
第一步,分配一块内存M;
第二步,在内存M上初始化Singleton对象,得到M的地址;
第三步,然后M的地址返回给instance变量。 // 最后赋值给instance变量
如果是这样执行,无论单线程还是多线程都不会有问题。
单线程不必多说,多线程下也是安全的(因为一定要第三步赋值给instance变量)
举例:线程A执行到第二步,假设被线程B线程切换,当然不会被切换,因为我们使用synchronized ,在instance没有完成赋值操作之前,线程A不会释放同步锁,所以线程B根本进不来。
所以,按照这个三步骤,可以保证多线程安全
![]() 2.3.3 第三,实际优化后的执行路径:instance = new Singleton();
2.3.3 第三,实际优化后的执行路径:instance = new Singleton();
instance = new Singleton();
第一步,分配一块内存M;
第二步,将M的地址赋值给instance变量;// 解释:这个时候Singleton对象还没有初始化,M地址为&M,但是注意,这里完成对instance变量赋值操作后,线程A就会释放同步锁,线程B就可以进来了,这就是指令重排序造成的懒汉式单例双重检查不安全的地方
第三步,最后在内存M上初始化Singleton对象。// 解释:这个时候再来初始化,但是内存M的地址没有给instance变量
如下,由于instance = new Singleton();底层对应的指令重排序,所以线程A第二步就是instance=&M,完成了对instance对象的修改,就会释放同步锁,就会被切换到线程B,这是instance==&M,因为instance已经被赋值修改,不再是null,所以线程B不会再执行自己的instance=new Singleton三步骤了,但是线程B看到M内存中没有初始化的Singleton对象,出错
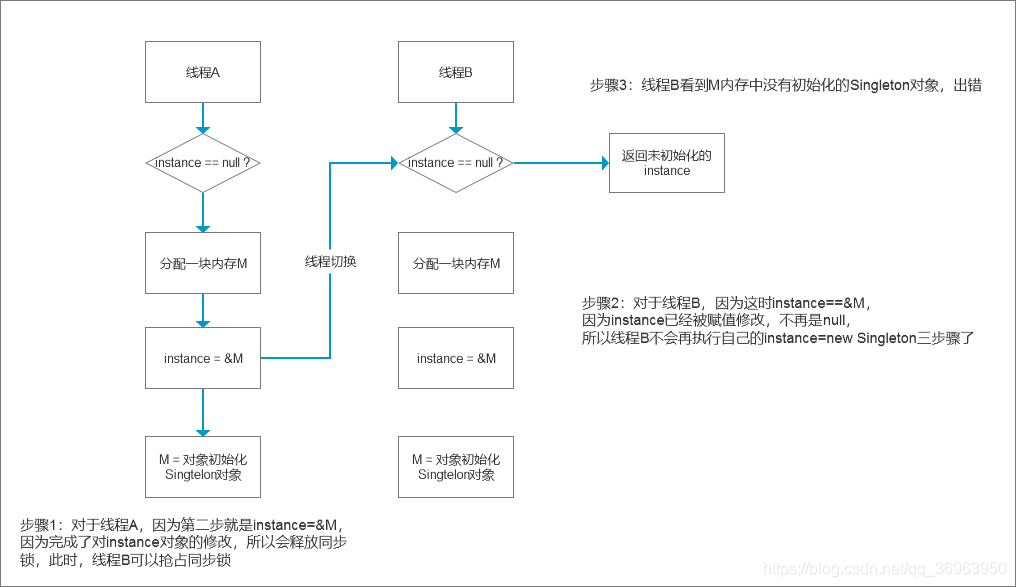
金手指:一句话小结指令重排序在多线程下的有序性问题(懒汉式单例的双层if判断为例)
1、不使用指令重排序,单线程和多线程下没有线程安全问题
单线程不必多说,多线程下也是安全的(因为一定要第三步赋值给instance变量)
举例:线程A执行到第二步,假设被线程B线程切换,当然不会被切换,因为我们使用synchronized ,在instance没有完成赋值操作之前,线程A不会释放同步锁,所以线程B根本进不来。
所以,按照这个三步骤,可以保证多线程安全
2、使用指令重排序,单线程下没问题,多线程下线程安全问题
由于instance = new Singleton();底层对应的指令重排序,所以线程A第二步就是instance=&M,因为完成了对instance对象的修改,就会释放同步锁,就会被切换到线程B,这时instance==&M,因为instance已经被赋值修改,不再是null,所以线程B不会再执行自己的instance=new Singleton三步骤了,但是线程B看到M内存中没有初始化的Singleton对象,出错
3、小结:从 CPU-缓存-主内存 到 执行引擎-工作内存-主内存,对于JMM,就是各个线程之间的执行引擎 指令重排序,所以造成有序性问题。
![]() 三、Java中如何解决可见性和有序性问题?(JMM:Java内存模型)
三、Java中如何解决可见性和有序性问题?(JMM:Java内存模型)
![]() 3.1 可见性和有序性
3.1 可见性和有序性
根本的原因:缓存导致可见性,编译优化导致有序性。
解决办法:禁用缓存和编译优化。如果全部的禁用缓存和编译优化,那我们的程序的性能会很差,所以我们的操作是按需禁用缓存以及编译优化。
![]() 3.2 JMM处理可见性和有序性问题
3.2 JMM处理可见性和有序性问题
JMM(Java内存模型)解决上面的问题主要是volatile、synchronized和final三个关键字,以及八项Happens-Before规则。
![]() 3.2.1 volatile:保证可见性
3.2.1 volatile:保证可见性
保证可见性不被破坏,就要禁用缓存,强制cpu运算器需要数据的时候直接从主存中拿,因为主存只有一块,对所有的线程都是可见的,从主存中拿就可以保证数据修改对所有线程可见,就解决了可见性问题。但是,不能对所有的变量都禁用缓存,会效率低下。
Java规定,对于使用volatile关键字修饰的变量,cpu对其读写,强制在主存中操作。但是,哪些变量需要使用volatile关键字修饰呢?这就是Java程序员的工作了,其实就是多线程临界区中使用的那些变量,一般只有一个或几个。
volatile保证可见性:告诉编译器,对这个变量的读写,不能使用CPU缓存,必须从内存中读取和写入。
public class VolatileExample {
int x = 0;
volatile boolean v = false; // 使用volatile修饰,保证可见性,从主存中读写
public void writer() {
x = 42; v = true; // 写到主存中 }
public void reader() { if (v == true) {
//x为多少?
System.out.println(x);
} }}12345678910111213141516在JDK1.5之前可能会出现x=0的情况,因为变量x可能被CPU缓存而导致可见性问题。1.5之后对volatile语义进行了增强,就是利用Happens-Before规则。
![]() 3.2.2 Happens-Before规则(JVM中已经定义的有序性:前面一个操作的结果对后续操作是可见的)
3.2.2 Happens-Before规则(JVM中已经定义的有序性:前面一个操作的结果对后续操作是可见的)
1、程序次序规则:在一个线程中,按照程序顺序,前面的操作Happens-Before于后续的任何操作。(解释:同一个线程中,或单线程下,有序性不变,执行顺序就是编写顺序)
2、volatile变量规则:对一个volatile编程的写操作,Happens-Before于后续对这个volatile变量的读操作。(解释:volatile强制保证有序性,作为happen-before 8条中的一条)
3、传递规则:如果A Happens-Before B,且B Happens-Before C,那么A Happens-Before C。(解释:没啥好说的)
4、锁定规则:对一个锁的解锁Happens-Before与后续对这个锁的加锁。(解释:上一个先解锁,下一个才能加锁,为保证一定解锁,解锁一般放在finally里面)
5、线程启动规则:如果线程A调用线程B的start()方法(即在线程A中启动线程B),那么该start()操作Happens-Before线程B中的任意操作。(解释:start()在启动线程之前)
6、线程终结规则:如果在线程A中,调用线程B的join()并成功返回,那么线程B中的任意操作Happens-Before于该join()操作的返回。(解释:join()返回在所有操作之后)
7、线程中断规则:对线程interrupt()方法的调用Happens-Before被中断线程的代码检测到中断事件的发生(解释:interrupt()早于中断线程)
8、对象终结规则:一个对象的初始化完成Happens-Before他的finalize()方法的开始。(解释:finalize()一定在结束对象之前)
![]() 3.2.3 final关键字(不可变)
3.2.3 final关键字(不可变)
JVM中五种线程安全级别:不可变、绝对线程安全、相对线程安全、线程兼容和线程对立,不可变是最高级别的线程安全,和常量一样,使用final修饰变量就是达到不可变
final修饰变量是,初衷是告诉编译器:这个变量生而不变,可以可劲儿优化。
逸出问题:
final int x;// 错误的构造函数
public FinalFieldExample() {
x = 3;
y = 4;
// 此处就是讲 this 逸出,
global.obj = this;}12345678在1.5以后Java内存模型对final类型变量的重排进行了约束。现在只要我们能够提供正确函数没有‘逸出’,就不会出问题了。
![]() 四、Java中如何解决原子性问题(互斥锁)
四、Java中如何解决原子性问题(互斥锁)
![]() 4.1 保证原子性(原子性两点:保证加锁才进入临界区、保证走完临界区代码解锁)
4.1 保证原子性(原子性两点:保证加锁才进入临界区、保证走完临界区代码解锁)
1、概念:一个或者多个操作在CPU执行过程不被中断的特性,称为原子性。
2、导致的原因:线程切换。
3、操作系统做线程切换是依赖CPU中断的,所以禁止CPU发生中断能够禁止线程切换。
(1)当在32位CPU上执行long型变量的写操作会被拆分成两次操作。写高32位和写低32位。
(2)单核:在单核CPU下,同一时刻只有一个线程执行,禁止CPU中断,意味着操作不会重新调度线程,也就是禁止了线程切换,获得CPU使用权的线程就可以不间断地执行,所以两次写操作一定是:要么都被执行,要么都没有被执行,具有原子性。
(3)多核:同一时刻,有可能有两个线程同时执行,一个线程执行在CPU-1上,一个线程执行在CPU-2上,此时禁止CPU中断,只能保证CPU上的线程连续执行,并不能保证同一时刻只有一个线程执行。
4、解决办法:互斥锁
金手指:
原因:造成操作的原子性被破坏的原因是线程切换
解决方式:禁止CPU中断(操作系统做线程切换是依赖CPU中断的,所以禁止CPU发生中断能够禁止线程切换)
Java禁止CPU中断的两种方式:同步阻塞synchronized和非同步阻塞CAS
同步阻塞synchronized和非同步阻塞CAS是如何保证原子性的?
1、保证加锁才进入临界区
解释:一定要线程安全才能进来 cas和synchronized都可以保证,cas一定要current==real才能进来,synchronized一定要获取到同步锁才能进来
2、保证走完临界区代码解锁
解释:里面的不出去,外面的不能进来,cas这里return next;之前都没有改变数据,所以里面的没出去,外面的不能进来;synchronized也可以保证这一点,里面的不执行完不释放锁,外面的进不来
![]() 4.2 锁模型理论,解决原子性问题
4.2 锁模型理论,解决原子性问题
![]() 4.2.1 简易的锁模型
4.2.1 简易的锁模型
所有的原子性(synchronzied lock cas)都是保证这两点:
第一,保证加锁才进入临界区
第二,保证走完临界区代码解锁
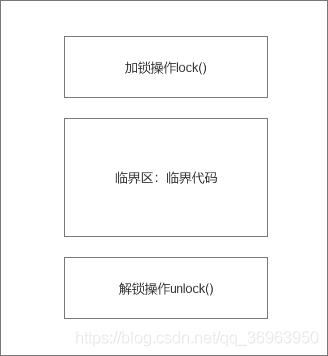
对于上图锁模型的解释:
第一,保证加锁才进入临界区:线程进入临界区之前,首先尝试加锁lock(),如果成功,则进入临界区,此时我们称这个线1程持有锁;否则就等待,直到持有锁的线程解锁;
第二,保证走完临界区代码解锁:持有锁的线程执行完临界区的代码后,执行解锁unlock()
![]() 4.2.2 改进后的锁模型(添加锁对象和受保护资源)
4.2.2 改进后的锁模型(添加锁对象和受保护资源)

对于上图改进后的锁模型的解释:
第一,在临界代码中,增加了受保护的资源R(解释:R 表示Resource);
第二,为了保护资源R就得为它创建一把锁LR(解释:LR 表示 Lock for Resource);
第三,对于新创建的锁LR,需要在进出临界区时添上加锁和解锁操作,即lock(LR)操作和unlock(LR)操作。
![]() 4.3 实践锁模型,synchronized五种用法
4.3 实践锁模型,synchronized五种用法
public class X {
//修饰非静态方法
synchronized void foo() {
//临界区 }
//修饰静态方法
synchronized static void bar() {
//临界区 }
//修饰代码块
Object obj = new Object();
void baz() {
synchronized (obj) {
//临界区 } }}1234567891011121314151617181920synchronized修饰静态方法相当于
class X {
//修饰静态方法
synchronized(X.class) static void bar() {
//临界区}}123456synchronized修饰非静态方法相当于
class X {
//修饰静态方法
synchronized(this) void bar() {
//临界区}}123456小结:synchronized可以修饰静态方法或静态代码块,同步锁是所在类的.class字节码对象;
synchronized可以修饰非静态方法或非静态代码块,同步锁是所在类的当前对象this;
synchronized可以修饰非静态代码块,同步锁是任意Object对象;
注意,方法上锁,要么this要么字节码对象,不能Object对象就好。
一共五种,小结如下表格:
| 修饰目标 | 锁 | |
|---|---|---|
| 方法 | 实例方法 | 当前实例对象(即方法调用者) |
| 静态方法 | 类对象 | |
| 代码块 | this | 当前实例对象(即方法调用者) |
| class对象 | 类对象 | |
| 任意Object对象 | 任意示例对象 | |
![]() 4.4 附加1:用synchronized解决count+1问题(锁:资源从1:1到N:1)
4.4 附加1:用synchronized解决count+1问题(锁:资源从1:1到N:1)
![]() 4.4.1 锁和受保护资源的关系是1:1关系(一个锁保护一个资源,两个临界区互斥关系)
4.4.1 锁和受保护资源的关系是1:1关系(一个锁保护一个资源,两个临界区互斥关系)
class SafeCalc {
long value = 0L;
synchronized long get() { return value; // 获取临界资源用synchronized包裹一次,读内存变量是一步操作,但是这里是long,long和double是64位,每次读32位,所有就不是原子操作了,所以要用synchronized包裹一次,防止被另一个线程调用addOne()打断 }
synchronized void addOne() {
value += 1; // value=value+1,三步操作,一定要用synchronized,防止被另一个线程调用get()打断 } }1234567891011大体的模型如下:
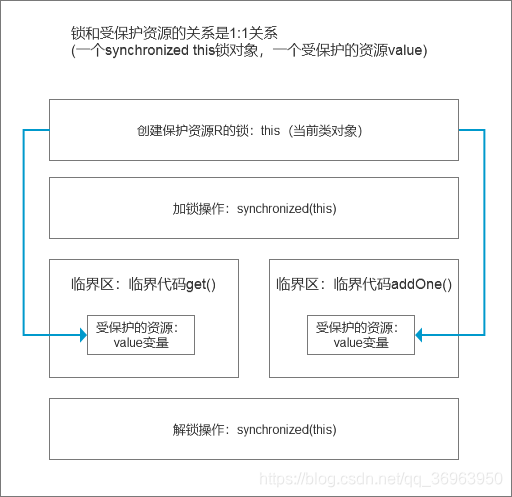
线程并发两要素:多线程,同步锁,这里一个锁(非静态方法锁对象是this),锁住一个变量value,起到原子化的作用,所以没有并发安全问题。
![]() 4.4.2 锁和受保护资源的关系是N:1关系(两个锁保护一个资源,两个临界区没有互斥关系)
4.4.2 锁和受保护资源的关系是N:1关系(两个锁保护一个资源,两个临界区没有互斥关系)
受保护资源和锁之前的关联关系是N:1的关系。
重写修改上面的代码
class SafeCalc {
long value = 0L;
synchronized long get() { return value; }
synchronized static void addOne() {
value += 1; }}1234567891011大体的模型如下:
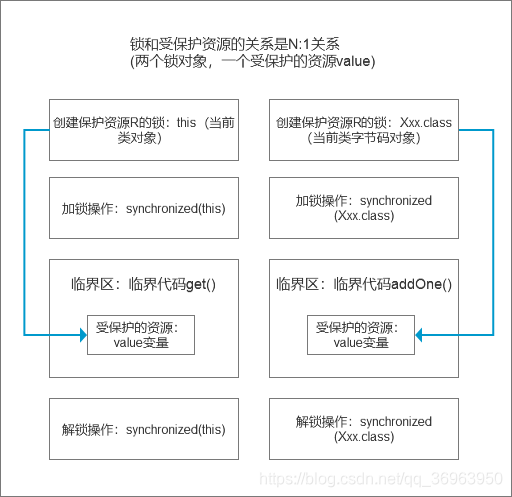
注意:这个时候的问题就是两个锁保护一个资源。因此这两个临界区没有互斥关系,临界区addOne()对value的修改对临界区get()也没有可见性保证,这就导致并发问题
线程并发两要素:多线程,同步锁,这里两个锁锁住一个变量value,没有起到隔离作用,所以存在并发安全问题。
![]() 4.4.3 锁:资源=1:N,用一把锁保护多个资源(属于同步锁对象高级用法)
4.4.3 锁:资源=1:N,用一把锁保护多个资源(属于同步锁对象高级用法)
4.4.3.1 一把锁保护多个资源:保护没有关联关系的多个资源
账号余额和账号密码没有关联关系
class Account {
// 锁1:保护账户余额
private final Object balLock = new Object();
// 账户余额
private Integer balance;
// 锁2:保护账户密码
private final Object pwLock = new Object();
// 账户密码
private String password;
// 取款
void withdraw(Integer amt) {
synchronized (balLock) { if (this.balance > amt) {
this.balance -= amt; } } }
// 查看余额
Integer getBalance() {
synchronized (balLock) { return balance; } }
// 更改密码
void updatePassword(String pw) {
synchronized (pwLock) {
this.password = pw; } }
// 查看密码
String getPassword() {
synchronized (pwLock) { return password; } }}123456789101112131415161718192021222324252627282930313233343536373839404.4.3.2 造成问题:一把锁保护多个资源:保护有关联关系的多个资源(银行转账的问题)
class Account {
private int balance;
// 转账
synchronized void transfer(Account target, int amt) { if (this.balance > amt) {
this.balance -= amt;
target.balance += amt; } }}1234567891011大体的模型如下:
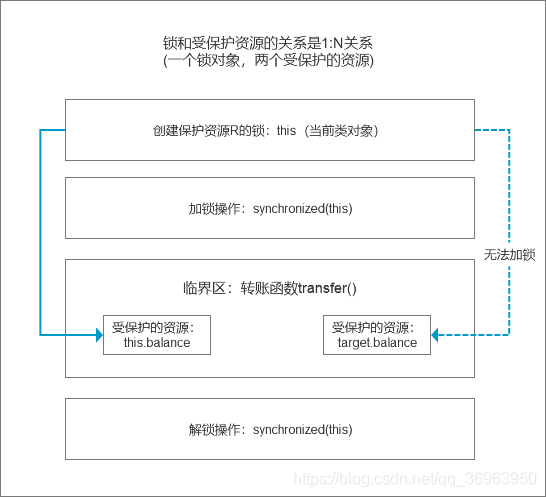
上面的代码的问题出在this这把锁上,this这把锁可以保护自己余额this.balance,却保护不了别人的余额target.balance,就像你不能用自家的锁来保护别人家的资产,也不能用自己的票保护别人的座位一样。
4.4.3.3 解决方式:一把锁保护有关联关系的多个资源(银行转账的问题)
再次修改上面的代码(下面的代码存在串行化的操作)
class Account {
private int balance;
// 转账
synchronized void transfer(Account target, int amt) {
synchronized(Account.class){
if (this.balance > amt) {
this.balance -= amt;
target.balance += amt; } } }}12345678910111213金手指:如果使用一把锁保护多个资源?
首先要分析多个资源之间的关系。
如果资源资源之间没有关系,很好处理,每个资源一把锁就可以了。
如果资源之间有关联关系,就要选择一个粒度更大的锁,这个锁应该能够覆盖所有相关的资源。
原子性的本质:操作的中间状态对外不可见。
![]() 4.5 附加2:死锁问题
4.5 附加2:死锁问题
![]() 4.5.1 死锁的引入:银行转账的问题
4.5.1 死锁的引入:银行转账的问题
对于上面,使用synchronize加一个this锁,可以保护this.balance但是无法保护target.balance,所以内部加一个synchronized(Xxx.class)静态锁,解决了这个问题,但是在现实生活中,没有办法锁住整个字节码对象。
在现实生活中,假设银行在给我能做转账时,要去文件架上把转出账本和转入账本都拿到手,然后做转账。会出现三种情况
(1)文件架上恰好有转出账本和转入账本,那就同时拿走;
(2)如果文件加上只有转出和转入账本之一,那这个柜员就先把文件架上有账本拿到手,同时等着其他柜员把另一个账本送回来;
(3)转出账本和转入账本都没有,那这个柜员就等着两个账本都被送回来。
即现实生活中使用两个锁对象synchronized(this)和synchronized(target)来加锁两个资源this.balance和target.balance,不能使用synchronized(Xxx.class),这种静态锁只有理论意义,在现实中模拟不出来,真正模拟出来就是同时锁住两个账本,但现实中一般不这么做。
于是我们将代码改成如下:
class Account {
private int balance;
// 转账
synchronized void transfer(Account target, int amt) {
//锁定转出账户
synchronized(this){
//锁定转入账户
synchronized(target){ if (this.balance > amt) {
this.balance -= amt;
target.balance += amt; } } } }}1234567891011121314151617这样的代码会发生新的问题,就是死锁的问题
大体模型为:

![]() 4.5.2 死锁:银行转账的问题,两次加锁产生死锁
4.5.2 死锁:银行转账的问题,两次加锁产生死锁
金手指1:两次加锁给死锁创造了条件
代码中两次加锁就会给死锁创造条件,代码中避免这样写,如果真的这样写了,处理处理呢?
概念:一组互相竞争资源的线程互相等待,导致“永久”阻塞的现象。
class Account {
private int balance;
// 转账
synchronized void transfer(Account target, int amt) {
//锁定转出账户
synchronized(this){//①
//锁定转入账户
synchronized(target){//② if (this.balance > amt) {
this.balance -= amt;
target.balance += amt; } } } }}1234567891011121314151617如何发生死锁(上面的代码)
(1)假设线程T1执行账户A转账账户B的操作,账号A.transfer(账户B);
(2)同时线程T2执行账户B转账账户A的操作,账户B.transfer(账户A);
(3)当T1和T2同时执行完①处的代码时,T1获得了账户A的锁(对于T1,this是账户A)而T2获得了账户B的锁(对于T2,this是账户B)
(4)之后T1和T2在执行完②处的代码时,T1试图获取账户B的锁时,发现账户B已经被锁定(被T2锁定),所以T1开始等待
(5)T2则试图获取账户A的锁时,发现账户A已经被锁定(被T1锁定),所以T2也开始等待
死锁的产生条件
(1)互斥,共享资源X和Y只能被一个线程占用;
(2)持有且等待,线程T1已经取得共享资源X,在等待共享资源Y的时候,不释放共享资源X
(3)不可抢占,其他线程不能强行抢占线程T1占有的资源
(4)循环等待,线程T1等待线程T2占有的资源,线程T2等待线程T1占有的资源,就是循环等待。
![]() 4.5.3 解决方式:死锁解决办法(破坏四个条件的其中之一)
4.5.3 解决方式:死锁解决办法(破坏四个条件的其中之一)
4.5.3.1 最常见:破坏占有且等待条件(一次性申请所有资源)
class Allocator {
private List<Object> als = new ArrayList<>(); // 仅仅一个局部变量而已,没有用
// 一次性申请所有资源 synchronized加锁,原子化 als.add(from); als.add(to);
synchronized boolean apply(Object from, Object to){
if(als.contains(from) || als.contains(to)){return false;} else {
als.add(from);
als.add(to); }return true; }
// 一次性归还所有资源 synchronized解锁,原子化 als.remove(from); als.remove(to);
synchronized void free(Object from, Object to){
als.remove(from);
als.remove(to);}}class Account {
// actr 应该为单例
private Allocator actr;
private int balance;
// 转账
void transfer(Account target, int amt){
// 一次性申请转出账户this和转入账户target,直到成功
while(!actr.apply(this, target));
try{
// 锁定转出账户
synchronized(this){
// 锁定转入账户
synchronized(target){if (this.balance > amt){
this.balance -= amt;
target.balance += amt;}}}} finally {
actr.free(this, target)}}}123456789101112131415161718192021222324252627282930313233343536373839404142解释上面的代码:
1、从Account类来看:会造成死锁的代码(synchronized(this) synchronized(target) )放在了while(!actr.apply(this, target)); 和 actr.free(this, target);中间,包裹一起来。
while(!actr.apply(this, target));加锁,使用synchronized保证只有一个线程进来,在该线程执行完成之前,其他的线程都不能进来,然后执行会发生死锁的代码(只有一个线程就不会死锁了),执行完成后解锁。
2、从Allocator类来看:同时申请资源apply()和同时释放资源free()。账户Account类里面持有一个Alloctor的单例(必须是单例,只能由一个人分配资源)。当账户Account在执行转账的时候,首先向Allocator同时申请转出账户和转入账户这两个资源,成功后再锁定这两个资源,当转账执行完,释放锁之后,我们需要通知Allocator同时释放转出账户和转入账户这两个资源。
问题:自旋带来的cpu消耗
一次性申请转出账户和转入账户,直到成功
while(!actr.apply(this, target));
如果上面的代码的执行时间非常短,这个方案是可行的,如果操作耗时长,这样CPU的空转的时间会大大的提升。
解决办法(等待-通知机制)
如果线程要求的条件(转出账本和转入账本同在文件架上)不满足,则线程阻塞自己,进入等待状态;当线程要求的条件(转出账本和转入账本同时在文件架上)满足后,通知等待的线程重新执行。
一个完整的等待-通知机制:
线程首先获取互斥锁,当线程要求的条件不满足时,释放互斥锁,进入等待状态;当要求的条件满足时,通知等待的线程,重新获取互斥锁。
4.5.3.2 破坏不可抢占条件
能够主动释放它占有的资源。synchronized不支持,后面会说JUC下面的包会支持
4.5.3.3 破坏循环等待条件,按序申请资源
破坏这个条件,需要对资源进行排序,然后按序申请资源
class Account {
private int id;
private int balance;
// 转账
void transfer(Account target, int amt){
Account left = this; //①
// 就是对申请资源定义顺序,任何线程都按这个顺序来,如下:
// 设A线程id<B线程id,A线程进来,A线程为left,B线程为right,
// 符合条件就交换,这里不符合条件
// 最后先加锁left A线程,再加锁right B线程
// 设A线程id<B线程id,B线程进来,B线程为left,A线程为right,
// 符合条件就交换:这里A线程设置为left,B线程设置为right
// 最后先加锁left A线程,再加锁right B线程
Account right = target; //②if (this.id > target.id) { //③
left = target; //④
right = this; //⑤} //⑥
// 锁定序号小的账户
synchronized(left){
// 锁定序号大的账户
synchronized(right){if (this.balance > amt){
this.balance -= amt;
target.balance += amt;}}}}}123456789101112131415161718192021222324252627282930313233将原来的
synchronized(this){
synchronized(target){12修改为
synchronized(left){
synchronized(right){12如何来按照顺序申请资源,即对申请资源定义顺序,任何线程都按这个顺序来,如下:
第一,设A线程id<B线程id,A线程进来,A线程为left,B线程为right,符合条件就交换,这里不符合条件,最后先加锁left A线程,再加锁right B线程;
第二,设A线程id<B线程id,B线程进来,B线程为left,A线程为right,符合条件就交换:这里A线程设置为left,B线程设置为right,最后先加锁left A线程,再加锁right B线程。
![]() 4.6 附加3:线程通信,synchronized等待队列:wait()、notify()、notifyAll()
4.6 附加3:线程通信,synchronized等待队列:wait()、notify()、notifyAll()
当一个线程进入临界区后,由于某些条件不满足(解释:就是我们的标志位不满足),需要进入等待状态。注意,这个等待队列和互斥锁是一对一的关系,每个互斥锁都有自己独立的等待队列。
第一,当调用wait()方法后,当前线程就会被阻塞,并且当前线程会进入到右边的等待队列中,这个等待队列也是互斥锁的等待队列。线程在进入等待队列的同时,会释放持有的互斥锁,线程释放后,其他线程就会有机会获得锁,并进入临界区。
第二,当条件满足时调用notify(),会通知等待队列(互斥锁的等待队列)中的线程,告诉它条件曾经满足过,将该线程出等待队列。
注意:因为notify()只能保证在通知时间点,条件是满足的。但是,被通知线程的执行时间和通知的时间点基本不会重合,所以当被通知的线程执行的时候,很可能条件已经不满足了(就是被其他同类竞争者线程插队了),被通知的线程要重新执行,仍然需要获取到互斥锁(因为插入到等待队列的时候已经释放同步锁了),notify()仅仅帮助这个线程从等待队列中逃离了而已。
大体模型如下:
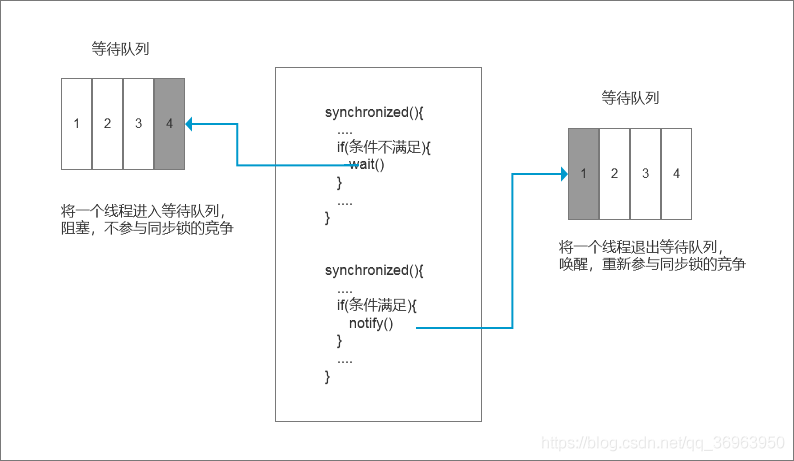
即:wait()将一个线程进入等待队列,阻塞,不参与同步锁的竞争;
notify()将一个线程退出等待队列,唤醒,重新参与同步锁的竞争。
重写刚才的例子
class Allocator {
private List<Object> als;
// 一次性申请所有资源
synchronized void apply(Object from, Object to){
// 经典写法
while(als.contains(from) ||als.contains(to)){
try{
wait(); // 这里wait()}catch(Exception e){}}
als.add(from);
als.add(to);}
// 归还资源
synchronized void free(Object from, Object to){
als.remove(from);
als.remove(to);
notifyAll(); // 这里多加一个notifyAll()}}123456789101112131415161718192021金手指:
// 一次性申请所有资源 synchronized加锁
synchronized boolean apply(Object from, Object to){
if(als.contains(from) || als.contains(to)){return false;} else {
als.add(from);
als.add(to); }return true; }
// 一次性归还所有资源 synchronized解锁
synchronized void free(Object from, Object to){
als.remove(from);
als.remove(to);}123456789101112131415tip1:lock有公平锁和非公平锁,synchronized只有非公平锁,lock实现公平加锁的底层是同步队列AQS,不是非循环单链表等待队列,等待队列synchronized也有。
tip2:
在lock中,同步队列FIFO保证加锁公平,等待队列FIFO保证阻塞唤醒公平;
在synchronized中,加锁解锁是抢占式非公平的,但是等待队列FIFO保证唤醒阻塞是公平,但是唤醒不保证可以公平地竞争到同步锁。
![]() 五、并发三方面问题
五、并发三方面问题
并发的问题主要是三个方面:安全性问题、活跃性问题、性能问题
![]() 5.1 安全性问题
5.1 安全性问题
1、本质的问题:程序按照我们期望的执行。
2、数据竞争:当多个线程同时访问同一数据,并且至少有一个线程会写这个数据的时候,如果我们不采取防护措施,那么就会导致并发的Bug。
3、竞态条件:程序的执行结果依赖线程执行的顺序。
4、上面的两种问题,都可以通过互斥这个技术方案,而实现互斥的方案有很多,CPU提供了相关的互斥指令,操作系统、编程语言也会提供相关的API锁。
![]() 5.2 活跃性问题
5.2 活跃性问题
1、死锁:线程会互相等待,而且会一直等待下去,在技术上表现就是线程永久的阻塞
2、活锁:线程没有阻塞,但仍然会存在执行不下去的情况。(尝试等待一个随机时间就可以了)
3、 饥饿:线程因无法访问所需资源而无法执行下去的情况。(不患寡,而患不均)(解决办法:保证资源充足,公平地分配资源,避免持有锁的线程长时间执行。)
![]() 5.3 性能问题
5.3 性能问题
1、尽量使用无锁 算法和数据结构
2、减少锁持有的时间
3、衡量标准
(1)吞吐量:单位时间内能处理的请求数量
(2)延迟:从发出请求到收到响应的时间
(3)并发量:同时处理的请求数量,随着并发量的增加、延迟也会增加。)
![]() 六、面试金手指
六、面试金手指
![]() 6.1 优化性能造成线程三个特性的破坏
6.1 优化性能造成线程三个特性的破坏
CPU与内存:缓存,CPU增加了缓存,以均衡与内存的差异;(但是带来可见性问题)
CPU与IO设备:进程、线程,操作系统增加了进程、线程,以分时复用CPU,进而均衡CPU与I/O设备的速度差异;(但是带来原子性问题)
编译程序指令重排序,编译程序优化指令执行次序,使得缓存能够得到更加合理的利用。(但是带来有序性问题)
![]() 6.2 解释缓存是如何造成可见性问题的,cpu分时时间片是如何造成原子性问题的,指令重排序是如何造成有序性问题的
6.2 解释缓存是如何造成可见性问题的,cpu分时时间片是如何造成原子性问题的,指令重排序是如何造成有序性问题的
金手指:一句话小结缓存在多线程下的可见性问题
1、单核cpu,只有一个cpu,所以只有一个缓存,所有的内存都是使用这个缓存,一旦缓存内存修改,所有cpu都可见,没有可见性问题
2、多核cpu,有多个cpu,每一个cpu中一个缓存,所以n个cpu就有n个缓存,n个缓存与同一个主存交互数据,主存中的数据对于所有缓存可见,但是不同缓存之间的数据是不可见的
单线程下,缓存从主存中拿数据,运算,然后再存入主存,没有问题
多线程下,两个线程使用两个不同的cpu,两个cpu缓存都从主存中拿数据,运算,然后再存入主存,这个过程中,每一个线程都是基于自己CPU缓存里的count值来计算,但是自己的缓存数据的修改只有自己可见,造成可见性问题
3、小结:从 CPU-缓存-主内存 到 执行引擎-工作内存-主内存,对于JMM,就是各个线程之间的工作内存不可见,所以造成可见性问题。
金手指:一句话解析分时时间片在多线程下的原子性问题
1、如果操作系统不支持分时使用CPU,即必须一个进程执行完成之后之后,再执行下一个进程,每一个进程的执行都不会被打断,每一个进程的执行都是原子的,不存在原子性问题。
2、如果操作系统支持分时使用CPU,一个进程执行读写磁盘或者读写内存的时候,会把CPU让出来,让给其他进程使用,如果获得CPU使用权的进程和当前进程修改同一变量,造成安全问题,该问题归根结底是因为打断了对一个变量读写的原子操作。
3、小结:从 CPU-主内存 到 执行引擎-工作内存-主内存,对于JMM,就是各个线程之间的工作内存访问主内存的操作无法原子化,所以造成原子性问题。
金手指:一句话小结指令重排序在多线程下的有序性问题(懒汉式单例的双层if判断为例)
1、不使用指令重排序,单线程和多线程下没有线程安全问题
单线程不必多说,多线程下也是安全的(因为一定要第三步赋值给instance变量)
举例:线程A执行到第二步,假设被线程B线程切换,当然不会被切换,因为我们使用synchronized ,在instance没有完成赋值操作之前,线程A不会释放同步锁,所以线程B根本进不来。
所以,按照这个三步骤,可以保证多线程安全
2、使用指令重排序,单线程下没问题,多线程下线程安全问题
由于instance = new Singleton();底层对应的指令重排序,所以线程A第二步就是instance=&M,因为完成了对instance对象的修改,就会释放同步锁,就会被切换到线程B,这时instance==&M,因为instance已经被赋值修改,不再是null,所以线程B不会再执行自己的instance=new Singleton三步骤了,但是线程B看到M内存中没有初始化的Singleton对象,出错
3、小结:从 CPU-缓存-主内存 到 执行引擎-工作内存-主内存,对于JMM,就是各个线程之间的执行引擎 指令重排序,所以造成有序性问题。
![]() 6.3 Java处理可见性和有序性问题(原因、解决方式、volatile、happen-before、final、synchronized)
6.3 Java处理可见性和有序性问题(原因、解决方式、volatile、happen-before、final、synchronized)
有序性根本原因:缓存导致可见性,编译优化导致有序性。
有序性解决办法:禁用缓存和编译优化。如果全部的禁用缓存和编译优化,那我们的程序的性能会很差。我们需要的是按需禁用缓存以及编译优化。
保证可见性不被破坏,就要禁用缓存,强制cpu运算器需要数据的时候直接从主存中拿,因为主存只有一块,对所有的线程都是可见的,从主存中拿就可以保证数据修改对所有线程可见,就解决了可见性问题。但是,不能对所有的变量都禁用缓存,会效率低下。
Java规定,对于使用volatile关键字修饰的变量,cpu对其读写,强制在主存中操作。但是,哪些变量需要使用volatile关键字修饰呢?这就是Java程序员的工作了,其实就是多线程临界区中使用的那些变量,一般只有一个或几个。
volatile保证可见性:告诉编译器,对这个变量的读写,不能使用CPU缓存,必须从内存中读取和写入。
1、程序次序规则:在一个线程中,按照程序顺序,前面的操作Happens-Before于后续的任何操作。(解释:同一个线程中,或单线程下,有序性不变,执行顺序就是编写顺序)
2、volatile变量规则:对一个volatile编程的写操作,Happens-Before于后续对这个volatile变量的读操作。(解释:volatile强制保证有序性,作为happen-before 8条中的一条)
3、传递规则:如果A Happens-Before B,且B Happens-Before C,那么A Happens-Before C。(解释:没啥好说的)
4、锁定规则:对一个锁的解锁Happens-Before与后续对这个锁的加锁。(解释:上一个先解锁,下一个才能加锁,为保证一定解锁,解锁一般放在finally里面)
5、线程启动规则:如果线程A调用线程B的start()方法(即在线程A中启动线程B),那么该start()操作Happens-Before线程B中的任意操作。(解释:start()在启动线程之前)
6、线程终结规则:如果在线程A中,调用线程B的join()并成功返回,那么线程B中的任意操作Happens-Before于该join()操作的返回。(解释:join()返回在所有操作之后)
7、线程中断规则:对线程interrupt()方法的调用Happens-Before被中断线程的代码检测到中断事件的发生(解释:interrupt()早于中断线程)
8、对象终结规则:一个对象的初始化完成Happens-Before他的finalize()方法的开始。(解释:finalize()一定在结束对象之前)
JVM中五种线程安全级别:不可变、绝对线程安全、相对线程安全、线程兼容和线程对立,不可变是最高级别的线程安全,和常量一样,使用final修饰变量就是达到不可变
final修饰变量是,初衷是告诉编译器:这个变量生而不变,可以可劲儿优化。
附加:synchronized同时保证原子性、有序性、可见性
![]() 6.4 Java处理原子性问题(原因、解决方式、两种方式和保证原子性的原因)
6.4 Java处理原子性问题(原因、解决方式、两种方式和保证原子性的原因)
原因:造成操作的原子性被破坏的原因是线程切换
解决方式:禁止CPU中断(操作系统做线程切换是依赖CPU中断的,所以禁止CPU发生中断能够禁止线程切换)
Java禁止CPU中断的两种方式:同步阻塞synchronized和非同步阻塞CAS
保证原子性的原因:同步阻塞synchronized和非同步阻塞CAS是如何保证原子性的?
1、保证加锁才进入临界区
解释:一定要线程安全才能进来 cas和synchronized都可以保证,cas一定要current==real才能进来,synchronized一定要获取到同步锁才能进来
2、保证走完临界区代码解锁
解释:里面的不出去,外面的不能进来,cas这里return next;之前都没有改变数据,所以里面的没出去,外面的不能进来;synchronized也可以保证这一点,里面的不执行完不释放锁,外面的进不来
![]() 6.5 附加1:锁与资源三种对应关系(锁:资源=1:1 N:1 1:N)
6.5 附加1:锁与资源三种对应关系(锁:资源=1:1 N:1 1:N)
金手指:如果使用一把锁保护多个资源?
首先要分析多个资源之间的关系。
如果资源资源之间没有关系,很好处理,每个资源一把锁就可以了。
如果资源之间有关联关系,就要选择一个粒度更大的锁,这个锁应该能够覆盖所有相关的资源。
![]() 6.6 附加2:死锁问题(四个条件和三个解决方式)
6.6 附加2:死锁问题(四个条件和三个解决方式)
金手指1:两次加锁给死锁创造了条件
代码中两次加锁就会给死锁创造条件,代码中避免这样写,如果真的这样写了,处理处理呢?
三种方式:破坏请求与等待条件(最常用:一次性申请资源)、破坏不可抢占条件(synchronized不支持,不能抢其他人手里的资源)、破坏循环等待条件(有序申请资源)
其中,互斥条件无法被破坏 (共享资源X和Y只能被一个线程占用,无法改变)
一次性申请资源:
1、从Account类来看:会造成死锁的代码(synchronized(this) synchronized(target) )放在了while(!actr.apply(this, target)); 和 actr.free(this, target);中间,包裹一起来。
while(!actr.apply(this, target));加锁,使用synchronized保证只有一个线程进来,在该线程执行完成之前,其他的线程都不能进来,然后执行会发生死锁的代码(只有一个线程就不会死锁了),执行完成后解锁。
2、从Allocator类来看:同时申请资源apply()和同时释放资源free()。账户Account类里面持有一个Alloctor的单例(必须是单例,只能由一个人分配资源)。当账户Account在执行转账的时候,首先向Allocator同时申请转出账户和转入账户这两个资源,成功后再锁定这两个资源,当转账执行完,释放锁之后,我们需要通知Allocator同时释放转出账户和转入账户这两个资源。
问题:自旋带来的cpu消耗
一次性申请转出账户和转入账户,直到成功
while(!actr.apply(this, target));
如果上面的代码的执行时间非常短,这个方案是可行的,如果操作耗时长,这样CPU的空转的时间会大大的提升。
解决办法(等待-通知机制)
如果线程要求的条件(转出账本和转入账本同在文件架上)不满足,则线程阻塞自己,进入等待状态;当线程要求的条件(转出账本和转入账本同时在文件架上)满足后,通知等待的线程重新执行。
一个完整的等待-通知机制:
线程首先获取互斥锁,当线程要求的条件不满足时,释放互斥锁,进入等待状态;当要求的条件满足时,通知等待的线程,重新获取互斥锁。
破坏循环等待条件,自定义申请资源顺序,任何线程都按这个来
将原来的
synchronized(this){
synchronized(target){12修改为
synchronized(left){
synchronized(right){12如何来按照顺序申请资源,即对申请资源定义顺序,任何线程都按这个顺序来,如下:
第一,设A线程id<B线程id,A线程进来,A线程为left,B线程为right,符合条件就交换,这里不符合条件,最后先加锁left A线程,再加锁right B线程;
第二,设A线程id<B线程id,B线程进来,B线程为left,A线程为right,符合条件就交换:这里A线程设置为left,B线程设置为right,最后先加锁left A线程,再加锁right B线程。
![]() 6.7 附加3:线程通信,synchronized等待队列:wait()、notify()、notifyAll()
6.7 附加3:线程通信,synchronized等待队列:wait()、notify()、notifyAll()
1、辨析wait() notify()的底层作用
wait()将一个线程进入等待队列,阻塞,不参与同步锁的竞争;
notify()将一个线程退出等待队列,唤醒,重新参与同步锁的竞争。
2、辨析lock synchronized的底层区别
(1)lock有公平锁和非公平锁,synchronized只有非公平锁,lock实现公平加锁的底层是同步队列AQS,不是非循环单链表等待队列,等待队列synchronized也有。
(2)在lock中,同步队列FIFO保证加锁公平,等待队列FIFO保证阻塞唤醒公平;
在synchronized中,加锁解锁是抢占式非公平的,但是等待队列FIFO保证唤醒阻塞是公平,但是唤醒不保证可以公平地竞争到同步锁。
![]() 6.8 并发三个问题
6.8 并发三个问题
安全性问题
1、本质的问题:程序按照我们期望的执行。
2、数据竞争:当多个线程同时访问同一数据,并且至少有一个线程会写这个数据的时候,如果我们不采取防护措施,那么就会导致并发的Bug。
3、竞态条件:程序的执行结果依赖线程执行的顺序。
4、上面的两种问题,都可以通过互斥这个技术方案,而实现互斥的方案有很多,CPU提供了相关的互斥指令,操作系统、编程语言也会提供相关的API锁。
活跃性问题
1、死锁:线程会互相等待,而且会一直等待下去,在技术上表现就是线程永久的阻塞
2、活锁:线程没有阻塞,但仍然会存在执行不下去的情况。(尝试等待一个随机时间就可以了)
3、 饥饿:线程因无法访问所需资源而无法执行下去的情况。(不患寡,而患不均)(解决办法:保证资源充足,公平地分配资源,避免持有锁的线程长时间执行。)
性能问题
1、尽量使用无锁 算法和数据结构
2、减少锁持有的时间
3、衡量标准
(1)吞吐量:单位时间内能处理的请求数量
(2)延迟:从发出请求到收到响应的时间
(3)并发量:同时处理的请求数量,随着并发量的增加、延迟也会增加。)
![]() 七、尾声
七、尾声
锁的由来,并发三特性全解析,完成了。
天天打码,天天进步!!!
https://blog.csdn.net/qq_36963950/article/details/109891572
上一篇: MySQL 字符串索引优化方案
下一篇: 【maven】批量修改项目各模块的版本号